
- Traitez-vous un grand volume de données dans un seul et même workspace FME?
- L’exécution de vos workspaces prend-elle trop de temps?
- Vos workspaces sollicitent-ils trop de mémoire vive – au point de causer des échecs sporadiques?
Si vous avez répondu « oui » à l’une de ces questions, l’enchaînement pourrait être votre solution!
L’enchaînement de workspaces, qu’est-ce que c’est?
C’est un principe selon lequel il est possible de diviser l’analyse et le traitement des données que vous entrez en plusieurs tâches, au lieu de tout faire dans une seule tâche.
Ce ne sont pas toutes les structures de données qui se prêtent à l’enchaînement des workspaces FME, mais lorsque c’est le cas, cette méthode peut être d’une grande efficacité. Si un workspace doit lire de multiples tables de base de données, fichiers ou couches d’un fichier, vous pouvez créer un enchaînement en traitant chaque élément séparément.
Comment cela fonctionne-t-il?
La méthode d’enchaînement la plus courante suit la logique « Parent/Enfant » (Master/Child) : dans ce cas, le workspace principal joue habituellement le rôle d’organisateur, générant des déclencheurs qui possèdent chacun un ensemble de paramètres précis à envoyer aux workspaces subordonnés. Ainsi, au lieu d’avoir à gérer toutes les données d’un bloc, ce dernier utilise des tâches séparées pour traiter les données analysées par le workspace principal.
La capture d’écran ci-dessous montre la première section de workspace principal, qui lit deux tables de base de données : « Municipalities » et « Layers ». Les entités de ces tables sont combinées dans une relation « un à plusieurs » au moyen d’un identifiant commun. Un objet, ou déclencheur, est alors créé pour chaque paire d’entités.
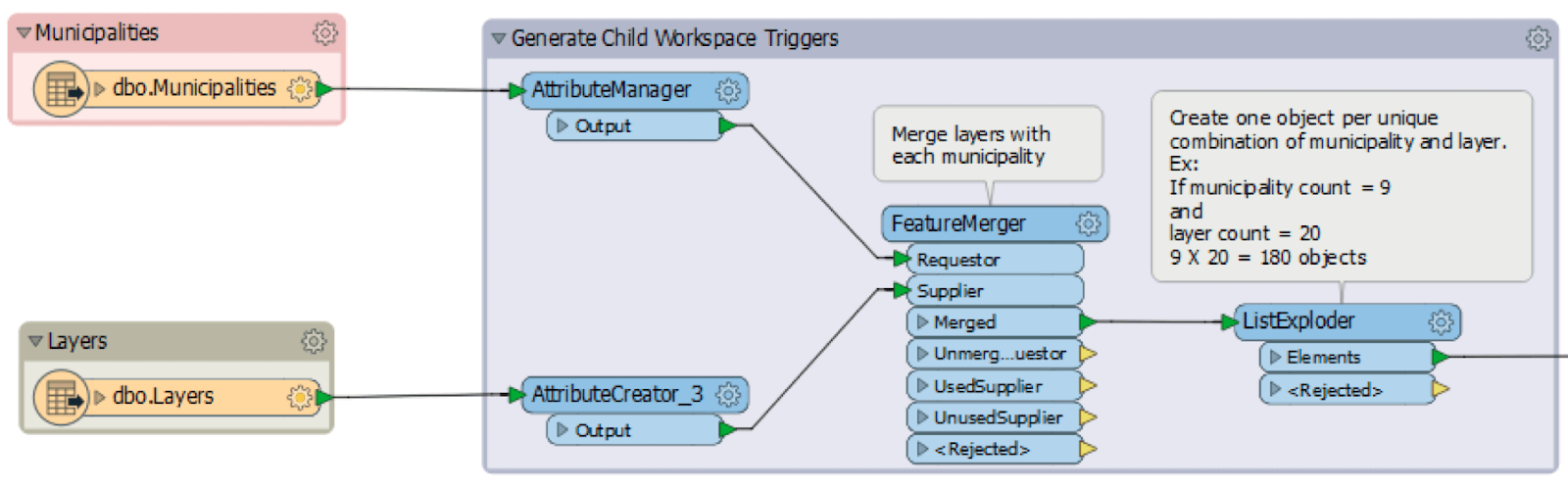
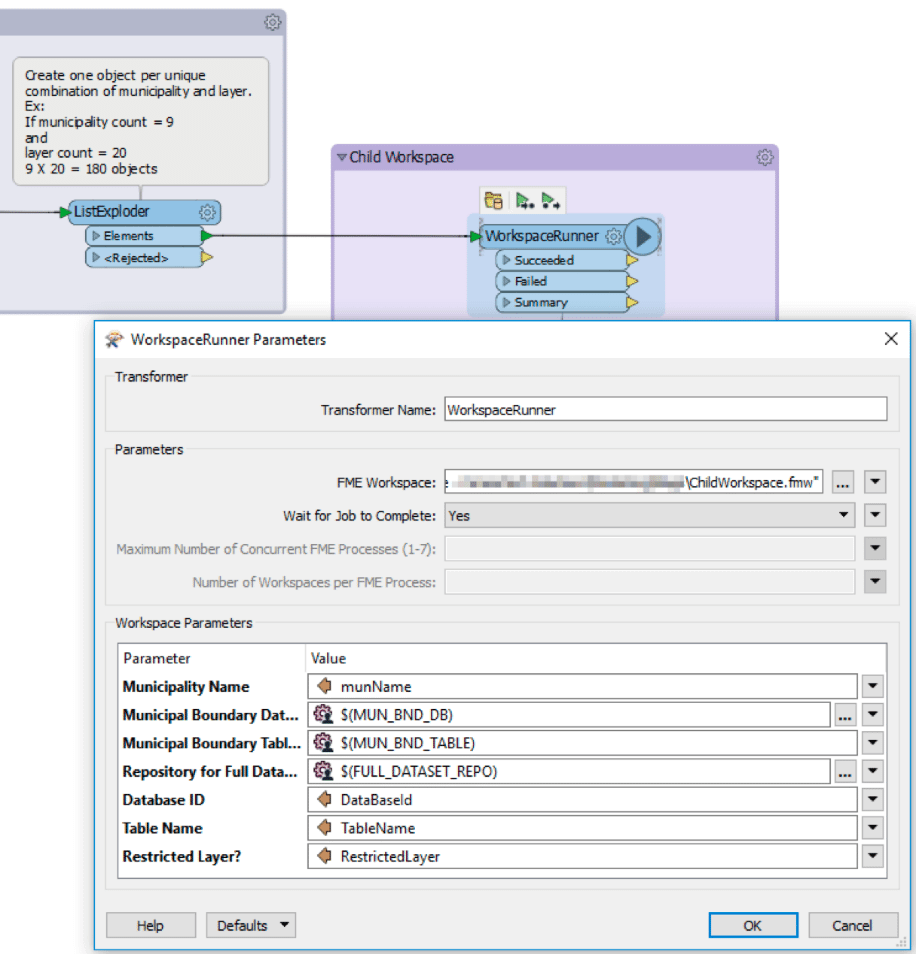
Par exemple, si vous avez 9 éléments dans Municipalities et 20 dans Layers, le workspace principal multipliera ces deux nombres pour générer 180 objets, chacun contenant son propre ensemble de paramètres qui déclencheront un workspace subordonné. La capture d’écran ci-dessous montre un WorkspaceRunner – le Transformer qui appelle le workspace subordonné – et les paramètres qui y sont définis. Certains de ces paramètres sont établis par ceux du workspace principal, mais d’autres découlent des valeurs d’attributs de chaque objet envoyé au workspace subordonné par le WorkspaceRunner.
Bien que certains processus vous laissent traiter toutes vos données en une seule tâche, la méthode par enchaînement comporte de nombreux avantages.
Utilisation réduite de la mémoire vive
Si le message suivant s’affiche dans le log, c’est signe que votre workspace FME utilise beaucoup de mémoire :
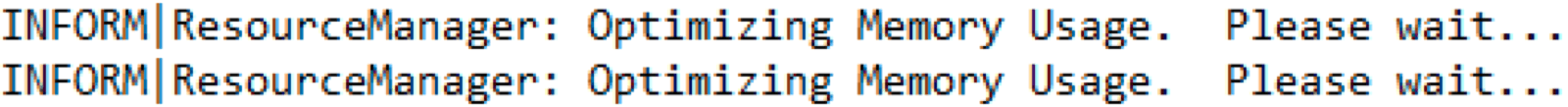
Ce message est souvent généré lorsque le workspace met tellement de données en cache que le système manque de mémoire virtuelle. Certaines transformations dans FME vont emmagasiner des données en cache, telles que l’utilisation de blocking transformers – FeatureMerger, Aggregator, Dissolver – et les opérations de type fanout. Les blocking transformers et les fanouts risquent de grandement solliciter de la mémoire, surtout s’il y a un grand nombre de données à traiter.
Réduire le nombre d’entités traitées par tâche réduit donc l’utilisation de la mémoire, puisque le cache se vide lorsque le workspace finit de s’exécuter.
Consignation et suivi des erreurs améliorées
Il peut être fastidieux d’analyser les logs générés, surtout lorsqu’une erreur fatale se produit. Heureusement, il vous est possible de configurer un enchaînement de façon à un log par exécution de workspaces subordonnés.
Dans le scénario vu plus haut, il peut se générer un total de 181 logs : un pour le workspace principal et 180 pour les workspaces subordonnés. Or, il est possible de faire le suivi des tâches des workspaces subordonnés dans le workspace principal au moyen des ports de sortie Succeeded (réussite) et Failed (échec) du WorkspaceRunner.
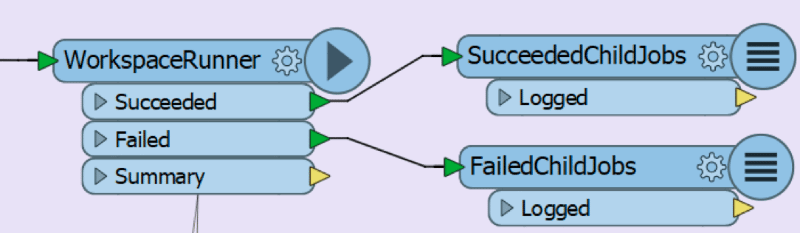
Il sera plus facile pour vous de détecter et de distinguer les erreurs qui se sont produites au cours d’une même tâche si vous prenez le temps d’analyser chaque log d’échec. Cela peut même vous aider à dégager des tendances dans les erreurs qui se répètent dans plusieurs tâches, comme des problèmes de connexion, des paramètres mal définis, et plus encore.
Rendement accru
En plus de diminuer l’utilisation de mémoire, l’enchaînement de workspaces vous laisse exécuter de multiples tâches en même temps. Ce traitement en parallèle peut vous faire gagner énormément de temps, comme il est possible d’exécuter sept tâches subordonnées à la fois. Le WorkspaceRunner exécute par défaut les tâches l’une après l’autre, mais si vous sélectionnez « No » au paramètre « Wait for the Job to Complete », un processus FME séparé sera lancé pour exécuter le workspace.
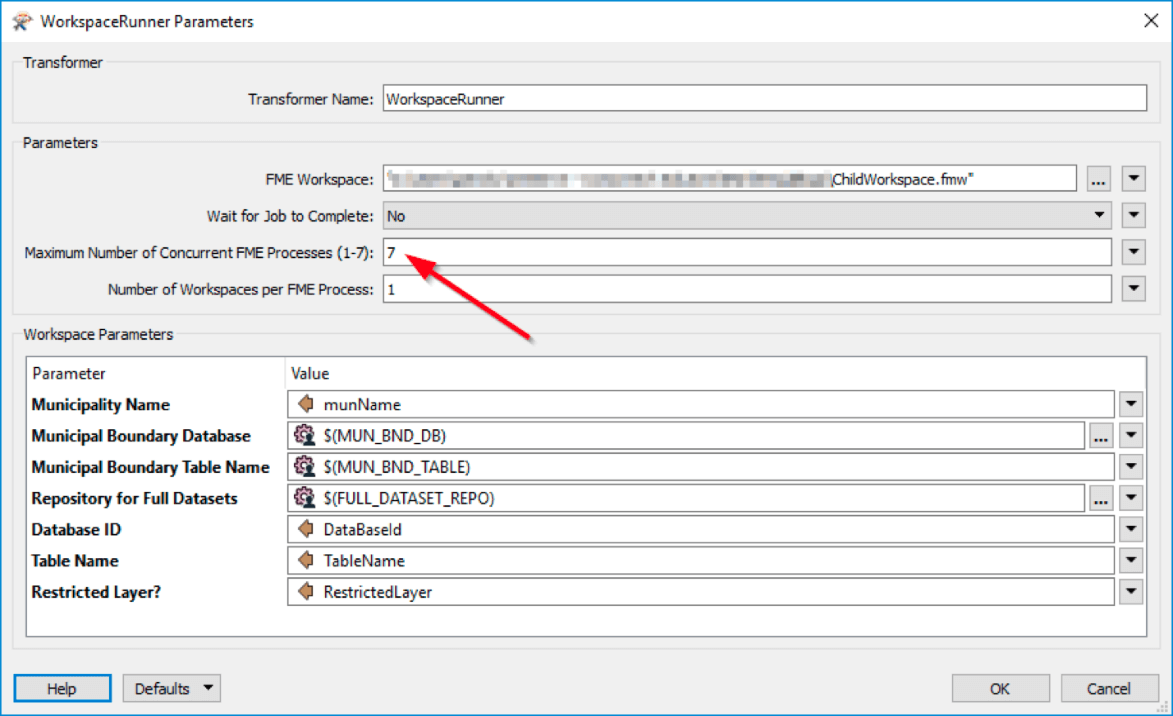
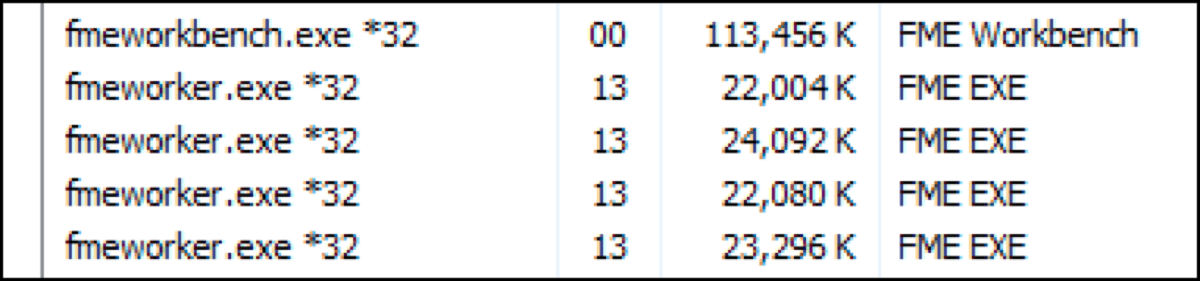
Ces processus s’affichent dans le gestionnaire de tâches sous forme d’instances « fme.exe » ou « fmeworker.exe ». Si l’on reprend le scénario de plus tôt, le workspace subordonné peut faire rouler un maximum de 7 instances en parallèle jusqu’à exécution des 180 processus, ce qui ira considérablement plus vite que s’il faut attendre la fin de chaque tâche pour lancer la prochaine.
Découvrez encore plus de conseils et d’idées de projets pour tirer le maximum de FME.
Besoin d’un coup de main dans la validation, la transformation, la conversion, la distribution de vos données ou dans quoi que ce soit d’autre?
Vous aimerez aussi :