
La lecture des données est un moment important dans tout workspace. Bien lire la donnée permet de s’assurer qu’on a toute l’information nécessaire au bon fonctionnement de celui-ci. Cette étape réduit également le besoin de manipulations supplémentaires via des Transformers dans le workspace. Également, la configuration des Readers aura un impact sur la rapidité et la lourdeur d’un processus.
Vous trouverez ci-bas certaines astuces vous permettant d’optimiser l’utilisation des Readers dans vos workspaces FME.
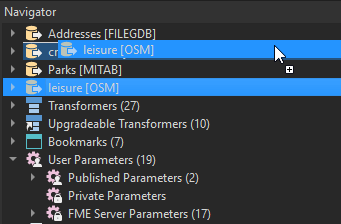
Ordre des Readers et des Writers dans le Navigator
Il est possible de modifier l’ordre des Readers et des Writers dans le panneau Navigator de FME Workbench en faisant un « click-and-drag ». Ceci permet de forcer la lecture et l’écriture d’un certain jeu de données de manière prioritaire dans le workspace.
Filtrer la donnée à la source pour ne pas la lire inutilement
Afin de rendre un traitement le plus efficace possible, il faut éviter de lire de la donnée qui n’est pas nécessaire. En lisant de la donnée qui ne sera pas utilisée, on alourdi le processus et par conséquent on le ralenti et/ou on utilise plus de ressources informatiques que nécessaire.
Il ne s’agit pas seulement de la filtrer tôt dans le workspace, mais directement au moment de la lecture (dans le Reader).
Pour y arriver, certains paramètres sont mis à notre dispositions dans les Readers FME :
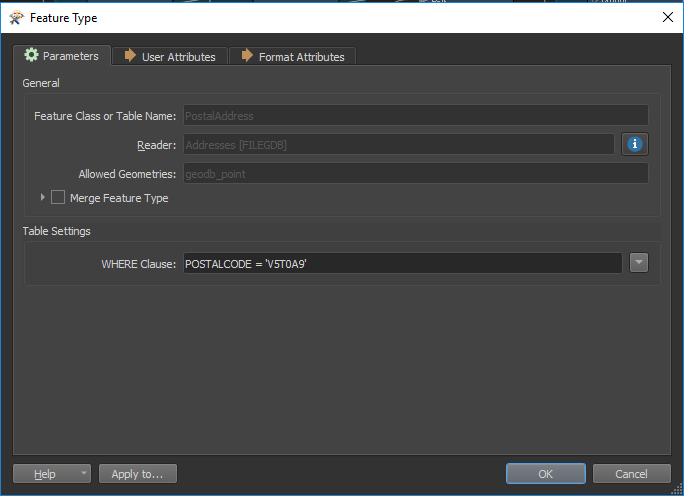
- WHERE Clause (pour les formats de type « base de données »). Cette fonction permet d’isoler les entités répondant à une certaine condition. La condition est appliquée directement à la lecture, évitant ainsi de lire l’ensemble du jeu de données et d’appliquer le filtre par la suite
- SQL Statement Before Read. Cette fonction permet d’exécuter une requête SQL avant la lecture d’une table dans une base de données. Ceci peut être utile par exemple, s’il est nécessaire de construire une vue temporaire avant la lecture.

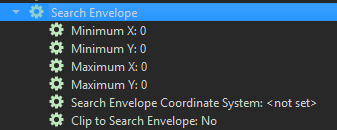
- Search Enveloppe (XMin, XMax, YMin, YMax). Cette fonction de spécifier une zone géographique au Reader afin qu’il lise uniquement les données se trouvant à l’intérieur de ce cadre. On évite ainsi de lire toutes les données qui sont à l’extérieur.
Enlever les attributs inutiles
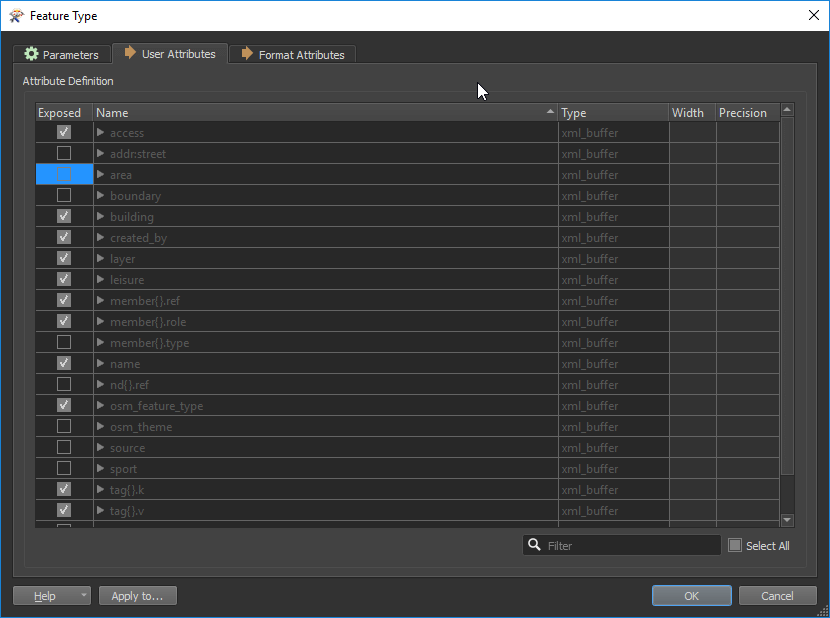
Dans les feature types des Readers, il est possible d’indiquer au workspace de ne pas lire certains attributs de la donnée. Ceci a pour effet d’alléger la donnée et par conséquent, le traitement. De manière générale, il est rare que tous les attributs d’une donnée soient nécessaires à chaque processus, c’est pourquoi il est intéressant de tirer avantage de cette fonction. Pour y arriver, il faut aller dans l’onglet « User Attributes » du « Feature Type » du Reader en question et décocher les attributs dont nous n’avons pas besoin.
Lire la donnée en cours de route
Parfois, il peut être avantageux ou plus stratégique de lire la donnée uniquement à partir d’un certain moment dans le workspace. C’est souvent le cas lorsqu’on veut créer une jointure avec une table de base de données, ou venant d’un jeu de données externe. L’utilisation de certains transformers permet donc de « lire » la donnée à un moment ultérieur et donc être plus efficace dans le traitement. Quelques transformers à considérer dans ce contexte :
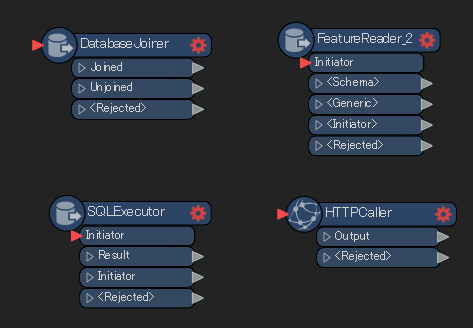
i. DatabaseJoiner
- Pour faire une jointure avec une table d’une base de données
ii. FeatureReader
- Pour faire une jointure avec un jeu de données externe
iii. SQLExecutor
- Pour lancer une commande SQL dans une base de données et retirer l’informations du résultat de la requête
iv. HTTPCaller
- Aller extraire de l’information venant d’une page web ou d’un API
Max Features to Read vs. Max Features to Read Per Feature Type
- Chaque Reader possède une série de paramètres s’appelant « Features to Read ». Ces options sont particulièrement intéressantes en phase de développement, car elles permettent de tester le processus sur un jeu de données plus restreint.
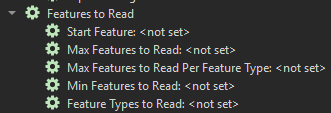
- Par exemple, en entrant une valeur de « 100 » à Max Features to Read », on indiquerait au workspace de ne lire que 100 entités pour ce processus.
- À noter que le paramètre « Max Features to Read Per Feature Type » ne fonctionne que pour les « Feature Types » étant définis explicitement dans le workspace. Il ne sera pas appliqué lorsqu’un filtre « Merge Feature Type » est défini ou lorsque les Readers sont en mode dynamique.
Conclusion
En somme, les éléments importants à retenir au niveau de la configuration des Readers sont les suivants:
- Lire uniquement la donnée nécessaire (filtrer à la lecture directement, exclure les attributs non-nécessaires). On cherche à éviter de trainer de l’information qui ne sera pas utilisée par le processus ou qui ne sera pas attendue dans le jeu de données final.
- Changer l’ordre des Readers dans le Navigator pour déterminer quel jeu de données est lu en premier.
- Parfois, le meilleur moment pour lire la donnée est en cours de route via l’utilisation de Transformers pour faire des jointures.
- En période de développement, tirer profit des paramètres « max features to read » pour faire des tests sur un groupe de données restreint et accélérer le développement.
Aimeriez-vous connaître davantage de trucs et astuces sur FME?