
Whether you’re an experienced user or simply getting started with FME, odds are you’ve dealt with lists before. Luckily, you don’t need to be an FME guru to fully leverage their potential. Below are some concepts that will quickly help you get started with lists!
1. What is a list?
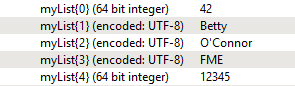
Similar to a list in Python, which is an ordered collection of items of any type, a list in FME allows features to have multiple values per attribute for a given record. Each separate value is stored in an index, or list element, which can be referenced by its position in that given list. This image displays the “myList” list attribute, which holds five values each referenced in a sorted index between 0 and 4.
You can leverage both attribute values found in tabular form and attribute values found in a list in an FME Workspace, which adds flexibility to your data. There are roughly 80 transformers in FME that can build or utilize lists.
2. Where are lists found?
Most commonly, whenever you’re joining attribute data in a one-to-many relationship you have the ability to generate a list. Storing multiple values for an attribute can be more efficient than a new record for each one-to-many relationship. This applies to both non-spatial joins (database joins) and spatial joins (intersecting and/or neighbouring features).
Splitting string values by delimiter also generates a list, where each split component is stored in a list element.
Web-based formats, such as XML or JSON, often store data in some form of list. Although the schema differs from one format to another, FME can effectively group elements into lists.
This image shows two JSON objects in the “stations” index with some associated data :

After reading and parsing the data in FME, the objects are now stored in a list called “array{}”.

This list can now be exploded into individual objects/records with its associated attributes exposed (capacity, eightd_has_key_dispenser, lat, lon, etc.):

3. What are the benefits of lists?
- Generating lists for one-to-many relationships in database and/or spatial joins can preserve all the joined data.
- List elements can easily be converted into tabular attributes, so you always have the option to store one or many list elements in a table.
- Splitting attribute values by delimiter can help store data more efficiently.
- Storing data in a structured indexed list prevents you from creating a large number of unnecessary table attributes, which can quickly become overwhelming.
Be careful! Just like when using attributes, you could end up with a ton of unnecessary data. It’s easy to get lost in the data, so clean up your lists as you go!
For more articles on FME and data processing
You may also like :
https://consortech.com/understanding-the-differences-between-fme-products/